Cloud cost optimization at scale part 1
Posted on January 21, 2024 • 4 minutes • 792 words
The best optimization is simply shutting things off
You work from 8am to 8pm. That’s 12 hours. What happened to the rest of the day? You go home. So you shut things down. That’s 50% cost saving right there.
Simple enough right?
Now add the following constraints:
- Imagine if you have an AWS organization with hundreds of workload accounts. I’ve seen org with over 700 accounts.
- Imagine if you want to support resources other than EC2.
- Now add Kubernetes to the mix. Now your EC2 VM is being controlled by autoscaling group/cluster autoscaler or karpenter. You can’t simply shut those off. They will be spin up right back.
- Your team is small. You cant have them support all the teams within organization. You need a solution that can be dynamic (to support multiple resources, different requirements from different teams,etc..) but also easy enough for other team to operate it themselves.
Cloud Automation Platform
I was thinking a bigger picture. I want a simple way to automate the whole cloud platform:
- Automate shutting down resources during off-work hours.
- Discover certain event, correcting things
- Etc…
I like Lambda, Step Functions and EventBridge. Let’s build something out of those.
Here’s what I had in mind initially
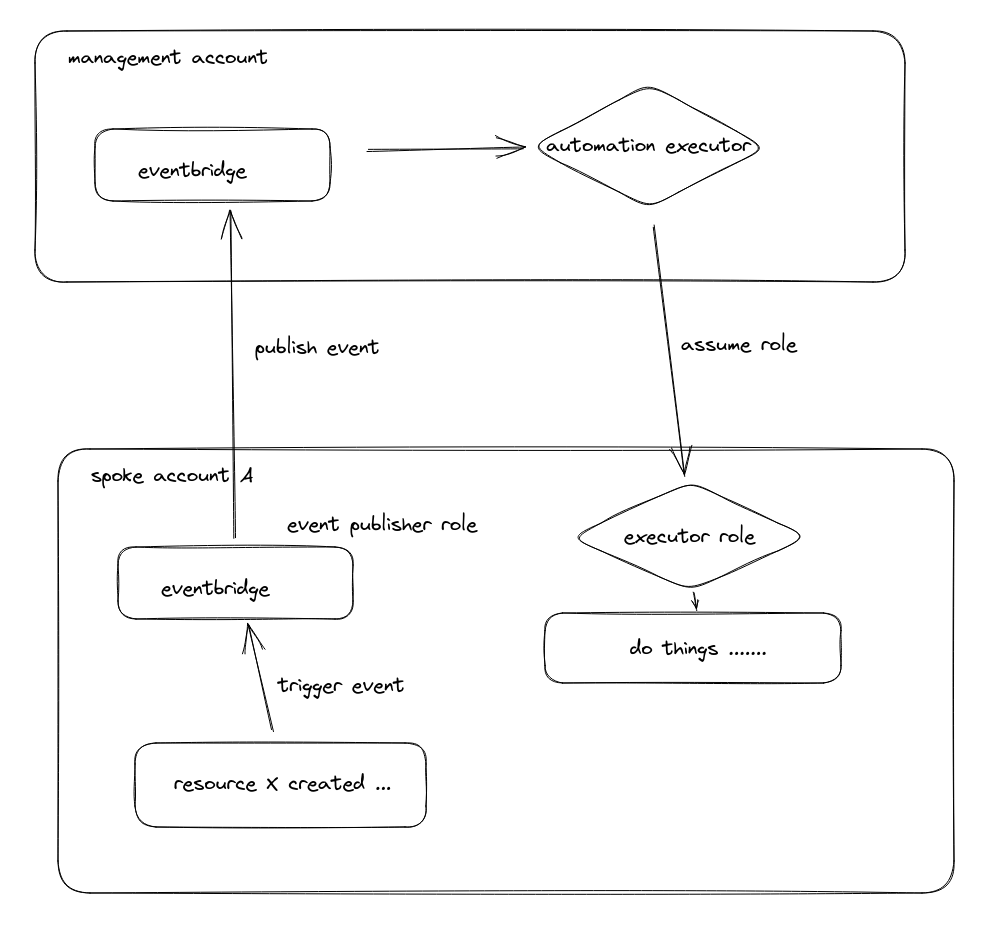
We changed the design a little bit by instead of assuming role, we just publish an event to the spoke account eventbus. We didn’t want the automation executor to have abilties to assume role everywhere in the org.
With this system in placed, we can do lots of stuff like
- Whenever an EKS cluster is created within our org, we want to inject some security baseline policies in.
- Whenever a Cloudwatch logs group created, we check for certain tag and if one presented, we ship it to a centralized account.
- Or we can do stuff like auto-shutdown resources like we want initially at the beginning of the post.
The deployment
Now for this to work, we need to have:
- (1) a consistent way of deploying stuff into spoke accounts.
- (2) We also need a way to protect those resources (this one is actually easy, we can use tag.)
As for (1), we are currently using AWS AFT . They have a mechanism for us to define baseline.
Baseline is whatever resources you want to deploy to every accounts within an Organization Unit. Sounds exactly like what we need right.
This kind of “baseline” is kinda like our agents, embeded in every spoke account.
The rest of this is just
- (1) agent discover stuff, send event to controlplane.
- (2) controlplane send command back to spoke account to act accordingly.
We built all these with Lambda, Step Functions and EventBridge.
We love EventBridge pattern matching so much we created a small, tiny Python module to be able to test pattern matching locally .
Back to the cloud cost optimization problem
Now that we have a generic mechanism to automate stuff in our org. Let’s do some $$ saving.
For this specific case, we don’t need our embedded agent to send us anything. We can simply send the “shutdown” command from controlplane.
We have a little database for config customization if needed. This is a small Git repo where owners/operators of those spoke accounts can customize their schedule according to their need.
What they can config is a pattern (EventBridge pattern style) along with what kind resouces to apply and the action accordingly. We also populate some more properties into the pattern payload like
is_holiday: bool. This one is pre-evaluated with our national public holiday. Users can then use this in their pattern matching. Eg. if holiday, do not turn them on at 8am.day_of_week: Mon, Tue, etc… Users can then use this field to add a rule to turn things on at 8am from Mon to Fri.- and more …
Once the agent receives the payload, they will act accordingly. For examples, EC2 will be send to a Lambda function that handle EC2 and RDS will be sent to another Lambda function that handle RDS. It’s quite easy to add another resouce to the supported list by simply adding more Lambda function handler.
We make this feature an opt-out feature on our non-production OU (Organization Unit). If they want to turn this off for certain resources, they will have to tag those resources accordingly.
The result
Our compute (EC2, RDS, etc…) non-production costs reduce by over 70% during off-work hours. We projected to save approx ~150k USD during 1 year (assume that our cost will not grow). It’s a small piece of our cost but we are still having many other optimizations wip.
There are certain workload that are a bit more complicated like Kubernetes I mentioned earlier. Those will be solved next in part 2 of this series. Stay tuned!